

1076
RNA structures (DSSR) / Re: What are the definitions of helix, stem, step etc in DSSR?
« on: March 10, 2013, 10:44:05 am »
Thanks for downloading the beta testing version of DSSR. I am working on a manuscript, and more details will be made available in due course. In the meantime, here is a short answer to your questions:
The default settings currently adopted in DSSR are based on my understanding of the conventions in the RNA structural world. I'd like to hear what users have to say and will make refinements accordingly. More functionality will be added the DSSR; with the current beta release, I've just kicked the ball rolling. Based on experience of supporting 3DNA and using other bioinformatics tools, I've created DSSR from the ground up to be trivial to set up and easy to use. Just play with it, and report back any issues you have.
HTH,
Xiang-Jun
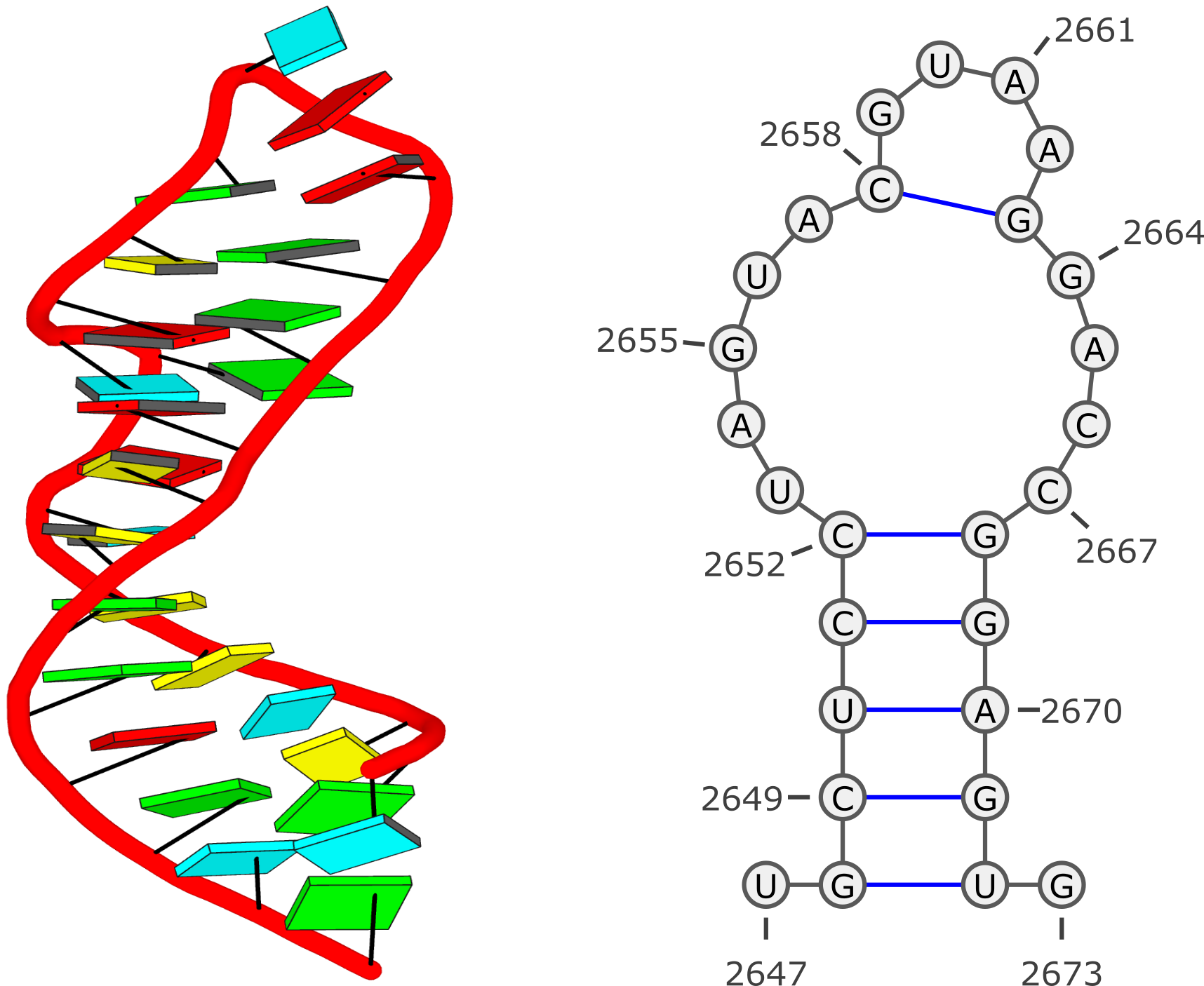
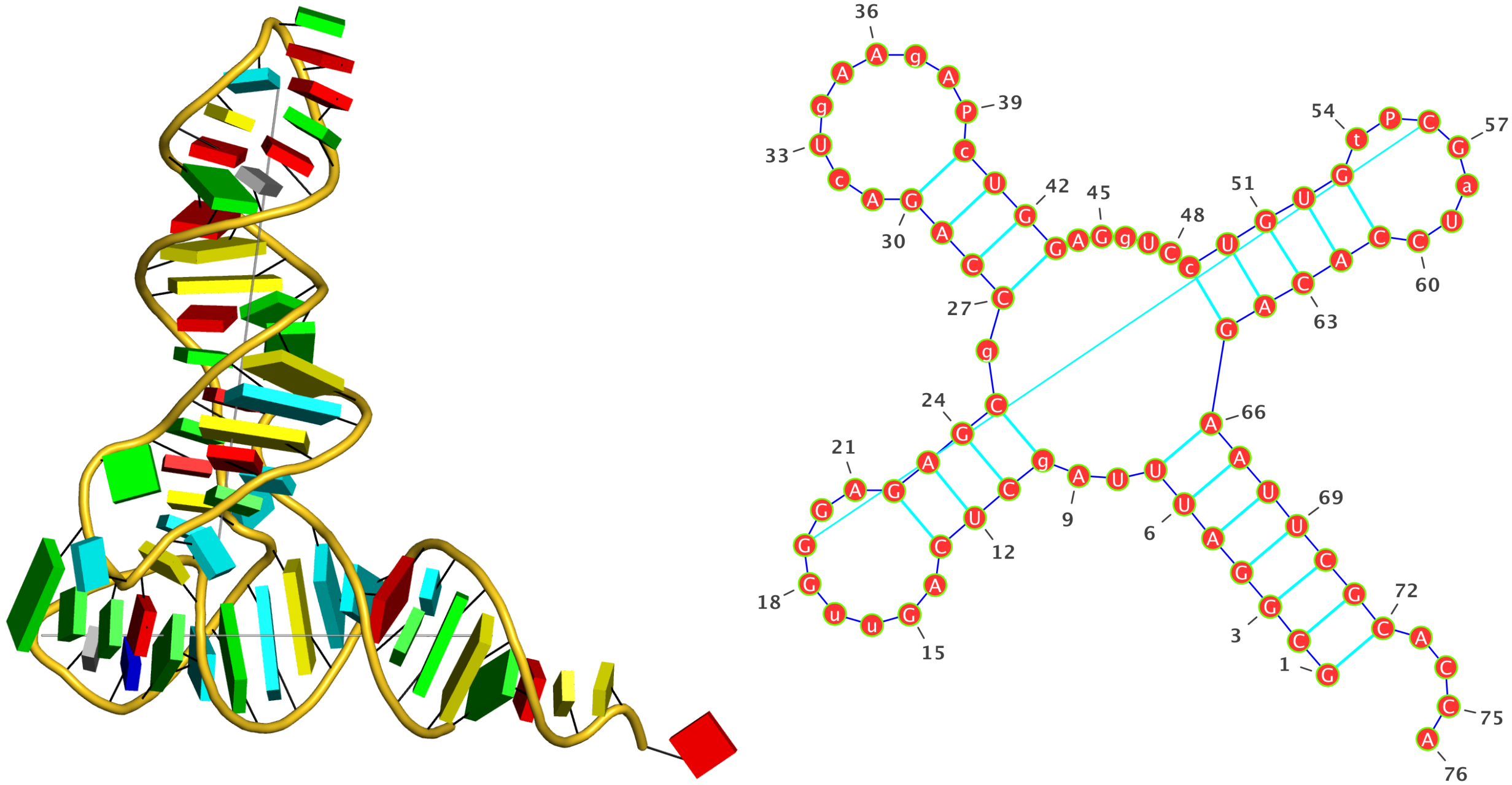
- DSSR defines a helix from purely a base stacking perspective, regardless of base-pair type or backbone connection. So the tRNA example (1ehz) has two helices, corresponding to the two arms of the stereotypical L-shaped tertiary structure.
- The stem are further restricted by canonical base pairs (Watson-Crick and G-U wobble), and backbone connections (each strand treated separately). So the same tRNA (1ehz) has four stems, corresponding to the famous tRNA cloverleaf secondary structure.
- The shortest helix or stem is composed of two base pairs. DSSR does not define a separate class of 'step'.
- As you may have observed in the two example output files, DSSR does treat lone (isolated) Watsoc-Crick (or G-U wobble) base pair separately.
The default settings currently adopted in DSSR are based on my understanding of the conventions in the RNA structural world. I'd like to hear what users have to say and will make refinements accordingly. More functionality will be added the DSSR; with the current beta release, I've just kicked the ball rolling. Based on experience of supporting 3DNA and using other bioinformatics tools, I've created DSSR from the ground up to be trivial to set up and easy to use. Just play with it, and report back any issues you have.
HTH,
Xiang-Jun
 . I'll get them fixed shortly -- hopefully by tomorrow. With the next release, the program would be quite robust, I believe.
. I'll get them fixed shortly -- hopefully by tomorrow. With the next release, the program would be quite robust, I believe.

{kind=link}