Hi paul,
Thanks for using 3DNA and posting your questions on the forum.
As detailed in
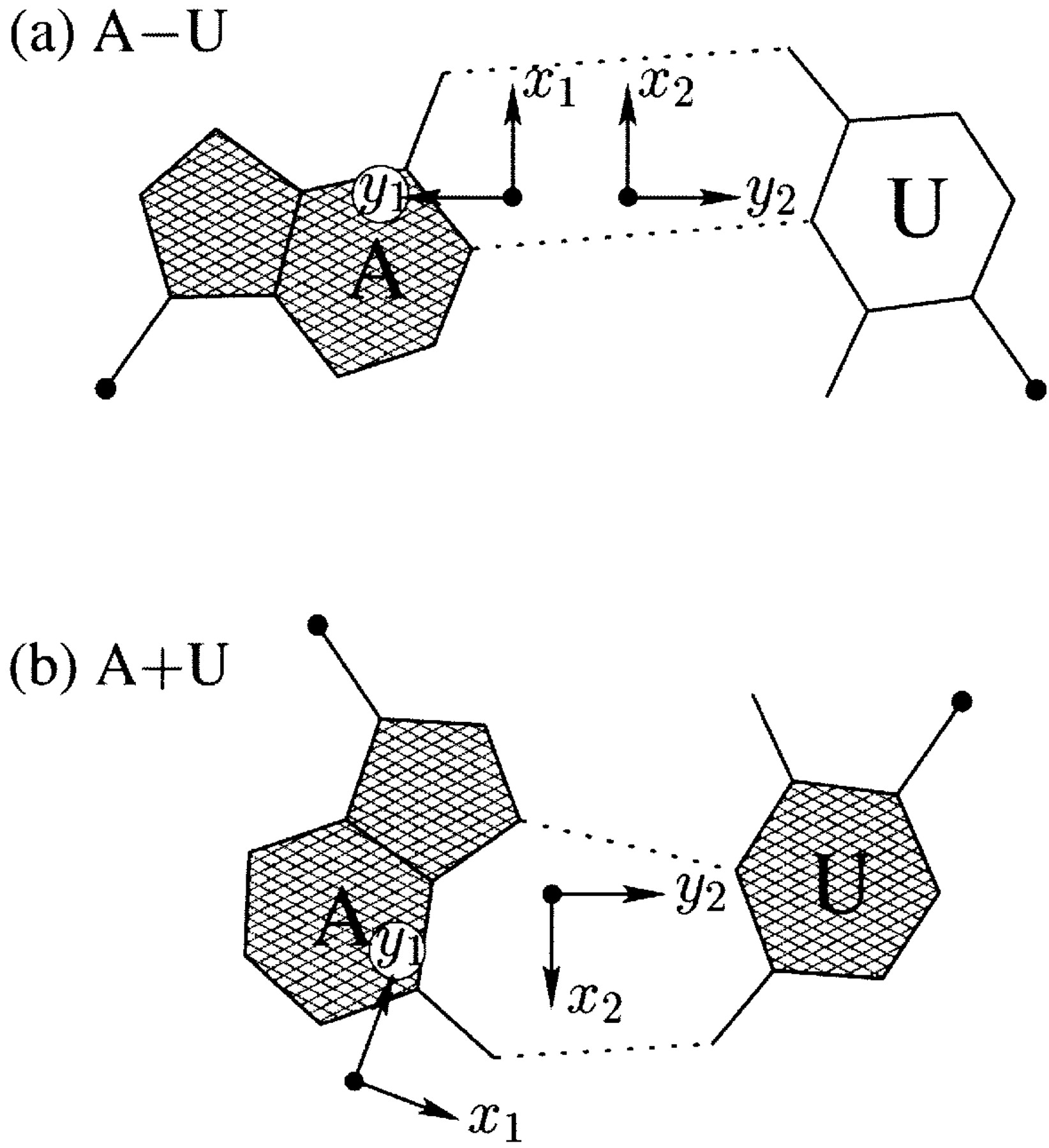
the 2003 3DNA NAR paper, the set of helical parameters (X-disp, Y-disp, h-Rise, Incl., Tip, h-Twist) parallels that of the stacking parameters (Shift, Slide, Rise, Tilt, Roll, Twist); each represents a
rigorous mathematical description of the relative geometry (position and orientation) of the two base pairs involved. You can verify the parameters by rebuilding an atomic model using the output file "
bp_helical.par" -- the RMSD of base atoms between 3DNA rebuilt structure and the original one should be virtually zero.
From your list of the parameters, it's clear that two CG/CG steps differ from each other: what is the RMSD between them? Do you see "something specific" there by using a visualization tool (PyMOL/Jmol)? As always, 3DNA outputted parameters should be checked along with other means and your understanding of your structure to make "sense".
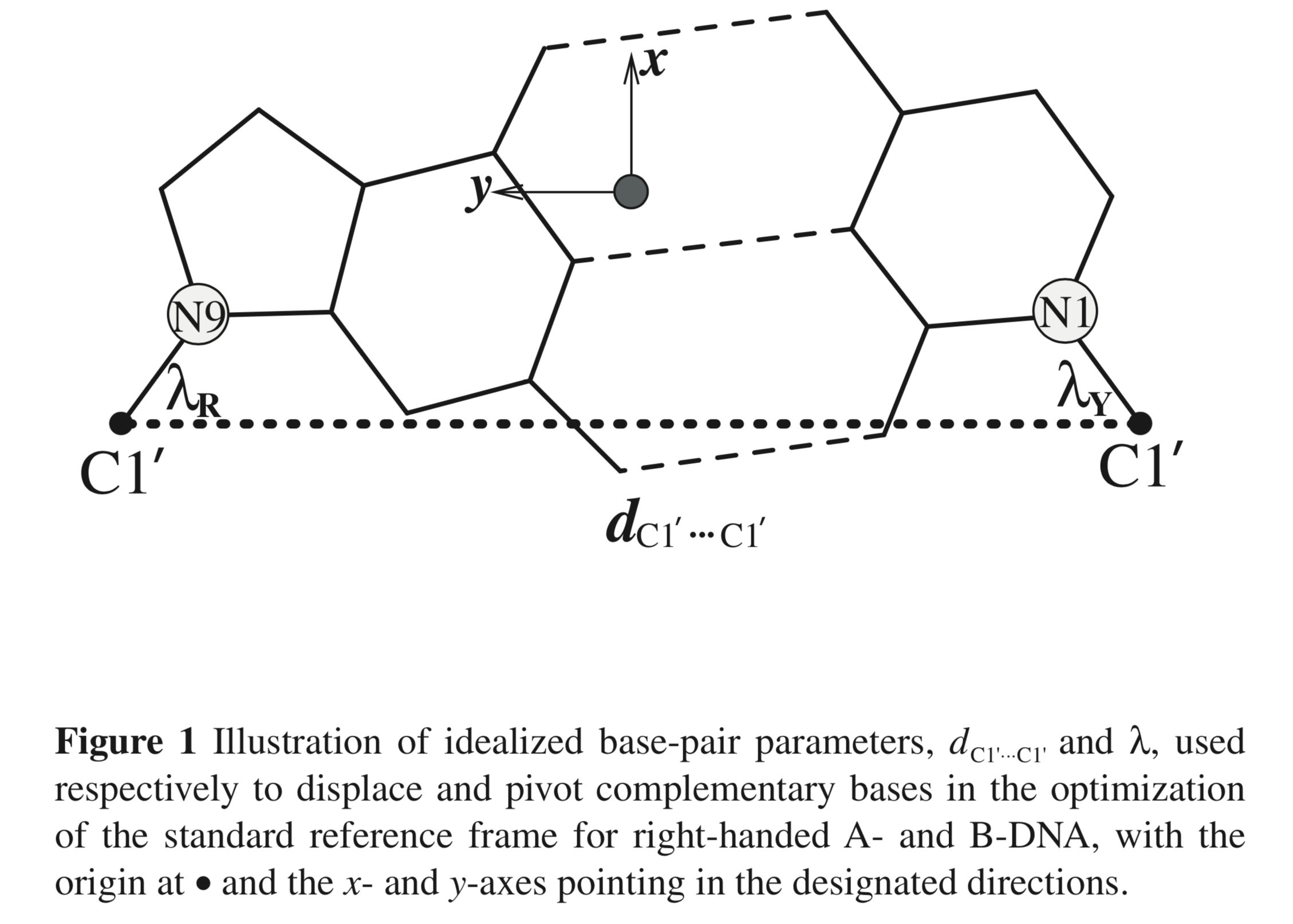
As elaborated in the thread "
A-DNA definition" on the forum, the Zp vs ZpH parameters are mainly used to distinguish right-handed A-, B- and TA-DNA forms. I have not checked how the ZpH values vary in left-handed Z-DNA.
Z-DNA has dinucleotide as a repeating unit, so you need to add (-6 + -54) or analyze alternating base pairs to get the ~-60° twist angle.
To get started with DNA structures, I highly recommend the book "
Understanding DNA: The Molecule and How it Works" by Calladine. You may check publications by
Dr. Remo Rohs on DNA shape (minor groove width).
HTH,
Xiang-Jun